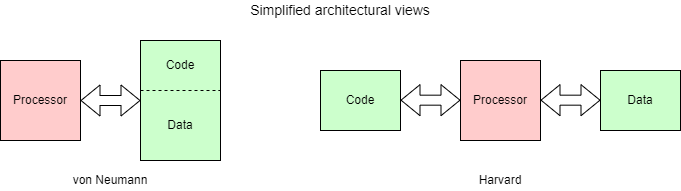
The classic computer architecture, as perceived by the programmer is the von Neumann architecture. A key characteristic is that a unified memory holds both instructions and data.
The most commonly cited alternative is the Harvard architecture where instructions and data are in separate address spaces.
The Harvard architecture offers more engineering flexibility: data
and instruction words can be different sizes. In particular it allows
instruction fetches in parallel with data movement, helping to
overcome the memory bottleneck.
The von Neumann architecture is usually more convenient for
programmers: the available memory can be partitioned dynamically into
code and data segments as is currently appropriate. Data and code can
be interchanged, e.g. loading then running a ‘binary’ file
or compiling a programme.
Most contemporary ‘big’ computers - x86, ARM etc. - use a von Neumann architecture. That is not to say their implementation is purely ‘von Neumann’. Some contemporary embedded controllers - notably the AVR used in the small Arduino controller boards - are Harvard architecture. Here's a memory map:

Another ‘different’ feature of the AVR is that its ‘registers’ are aliased into the (data) memory space.
Exploration: you might try looking at an AVR datasheet, both to see an example of a small system datasheet. Don't memorise all 357 pages (!) but the block diagram on p.3 and the data memory map (p.17) might be worth a glance.
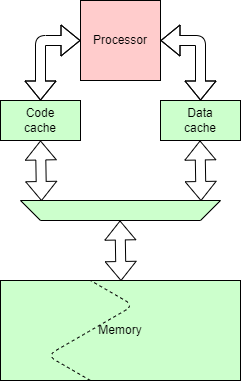
Although most high-performance processors present a von Neumann programming model they typically have Harvard-style architecture at cache level with separate buses. These connect different processor pipeline stages to parallel caches. This allows data loads and stores to run in parallel with instruction fetches, increasing the effective memory bandwidth. Unification of the memory model is provided below this so mostly this looks like a von Neumann space to the programmer.
Although the software rarely needs to accommodate this there are
potential problems. For example, if code is
self-modifying
- i.e. it tries to write or alter its own instructions - the writes
will alter the data cache but usually won't change any copy held in
the instruction cache.
Although explicit self-modification is usually a Bad Idea it is
implicit in techniques like
JIT
compilation and
dynamic
binary translation which are now quite widely employed.
When object code has been written it is usually necessary to provide some sort of memory barrier which ensures that the writes are complete before trying to read them and, probably, a cache flush to ensure any cached instructions are up to date.
Another issue is how the address space is organised in multiprocessors. There are many ways to organise this but the most commonly encountered is a multi-core processor where there is a single (von Neumann) address space with the various processor ‘cores’ - each a fully capable processor - share access to this memory.

This model simplifies programming and operating system organisation
since an active process can be assigned and reassigned to any core.
You might be able to see this if you have a multi-core system
(likely!) and some form of performance meter or system monitor.
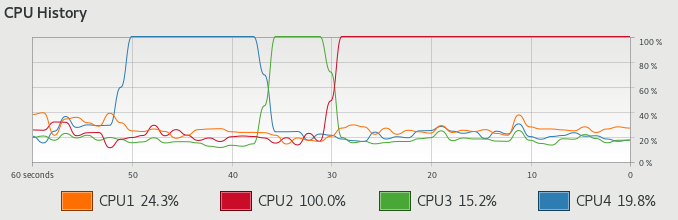
There's an example below with a single busy process (plus low-level
background activity) on a quad-core Linux system.
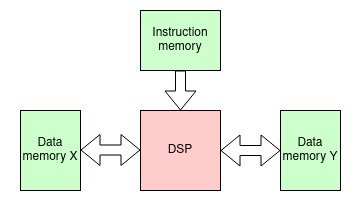
Sometimes there is sufficient demand that processors with ‘different’ requirements are produced. One example is the class of Digital Signal Processors (DSPs). Frequent requirements include matrix multiplication which involves reading pairs of operands at high speed. Thus they may have two data buses (or more!).
Next: Memory hierarchy.