Discussion questions
Why can conflicts occur even when there is some unused cache capacity?
Why is higher associativity desirable in small caches?

It is traditional at about this point to classify cache misses under three headings (all beginning in ‘C’).
Discussion questions
Why can conflicts occur even when there is some unused cache capacity?
Why is higher associativity desirable in small caches?
When a cache miss has occurred a check is made that the requested address can be cached; some addresses, such as I/O peripheral locations should not be considered for cacheing. Assuming the location is in a cacheable line it is necessary to allocate a suitable place.
In a direct mapped cache this is trivial: there is only one place the fetched line can go! In a set associative cache the set the line is going into must be chosen; within the set the position is still predetermined by the address. In a fully associative cache any line can be chosen.

Where there is a choice, the first choice may be a place which is currently invalid. However at some point all the candidate lines will be valid and there is a capacity miss; an existing line must be ejected to make space.
The ideal cache replacement mechanism would eject a line that was never going to be used again. Failing that it would eject the line which would be wanted at the most distant future time. All this requires determining the future behaviour of the software which is beyond current technology and likely to remain so.
There are various practical allocation algorithms which can be built. These include:
Discussion problem
How can you implement a Least Recently Used (LRU) replacement algorithm?
- First, consider how you might do this in software.
This might be used in a web page cache in a browser, for example.- How might LRU apply to a direct mapped cache?
- How might LRU be implemented in hardware to support a 2-way set associative cache?
- How much harder is hardware LRU for a 4-way set associative cache?
- How about a fully-associative hardware cache?
Whilst picking a cache line it may be possible to be
fetching the new line in parallel. It is important to start
this early because latency is the thing which slows everything
down. The fetch will be a cache line so the fetch operation is
a burst of data with some confidence that spacial
locality will reduce the total number of misses (and resulting
latency penalties).
Modern memory systems are optimised for efficient burst access rather
than single word access.
Whilst the fetch is taking place, what is the processor doing?
In the basic case it is stalled thus losing performance. Here
the latency impact can be serious. Unlike a virtual memory page miss,
where the wait would be very significant and it is economic
to context switch these misses are going to be tens or hundreds
of cycles (maybe around 10 μs) so this does not make sense;
anyway process switching would discard (‘flush’)
the cache contents!
Thread switching is more credible; a hyperthreaded
processor has hardware support to do this. More on this later.
Consider what is involved in thread switching and think of reasons why this would not be feasible in software during a cache miss.
Write operations can be buffered (more on that later, too). However reads have a dependency so there is not much that the thread can do until the read latency has elapsed.
One way of avoiding the penalty caused by cache misses is to reduce the number of cache misses. This can be done by speculation – predicting and fetching lines before they might be wanted.
In some sense, the expectation of spatial locality will help with fetching. For example, following a ‘jump’, it is likely that several successive instructions will be wanted. This could be extended in a (code) cache by observing the pattern of instruction fetches and looking ahead. (This would have to have some way of ensuring the next line was not already cached, which would be another cost.) Since, on average, a typical programme branches about every seven instructions, this might or might not make sense.
Data references may also be predicted and having data cached can be
especially important when dealing with big data sets. Hardware to
monitor data access patters has (at least) been investigated. In some
applications with big data sets – matrix multiplication for
example – access patterns may be quite predictable although not
have much spatial locality.
Regular access patterns typically arise from iterating loops. A
facility built into many instruction sets is a
‘prefetch’ instruction which is like a
‘load’ but doesn't care about the data. If a prefetch is
inserted with an address calculation for the next iteration of
a loop then the fetch latency can be hidden and there should be a
cache hit when the ‘real’ load is executed. (This does,
of course, mean the penalty of an extra instruction to start the fetch
in every iteration, but it can be worthwhile.) This is sort-of
speculation but guided by the programmer.
Lastly, since we're at the hardware/software boundary, it may be possible to structure code and data structures to reduce the number of cache misses. This can yield significant performance increases in some cases.
The following demonstration shows four different cache write
policies. Commands are interpreted for all the alternatives in
parallel but the statistics will vary. In all cases a cache access
takes one cycle and a memory access takes five cycles.
Revision: the process should be familiar to some extent
from paging memory on and off disk by an operating
system.
*A write buffer is a queue which allows write operations to fire-and-forget, alleviating their latency. It has its own problems: more on this later in the module.
Note: in this demonstration the memory is shaded to indicate the lines which are invalid – i.e. that line is ‘dirty’ in the cache (copy back only, of course). This state is not kept explicitly as part of the memory system. Its use here is simply to help with visualisation.
In the demonstration, the timing of the write buffered examples is optimistic for a couple of reasons:

Every so often there is a need to flush a cache – i.e. invalidate its contents. The most common reason is probably a context switch where the translation of virtual addresses is redefined. This means that the virtual-addressed cache (usually just the ‘level 1’ cache) has to be dumped; the TLB will need to go, too.
In a write through system this is easy; the memory is up to date so
all the cache entries can simply be invalidated. In a copy-back
system the cache must be scanned and all the dirty lines must
be written back. This is time-consuming! The mechanism for doing
this may be built into the hardware but often it is a responsibility
of the (OS) software to clean up the cache.
In all cases, following the flush the cache has to be refilled so
there will be a spate of misses and, thus, a significant performance
penalty. It is not something which it is desirable to do too
frequently.
If a write miss occurs, is it a good idea to fetch and cache
the line which contains that data? In particular with a write through
policy this may not be the most efficient choice in the short term.
On the other hand, temporal locality suggests that the line may
be read again soon afterwards so having it cached will then be
convenient. There is no absolutely ‘right’ answer.
The example above does write allocation.
Discussion problem
Can you think of a credible example of a case where allocation-on-write would be inefficient?
It isn't possible to say definitively. Copy back generally reduces the memory activity which can be a significant power saving. Write buffering can hide some of the memory latency by making write operations ‘fire and forget’. Of course these expedients also make the cache control mechanisms more complex and they may not prove to be economic.
When there are multiple cache levels, different levels may have different associativity and so forth. Note also (again!) that a level 1 cache is likely to use virtual addressing whereas ‘lower’ cache levels will use physical addresses.
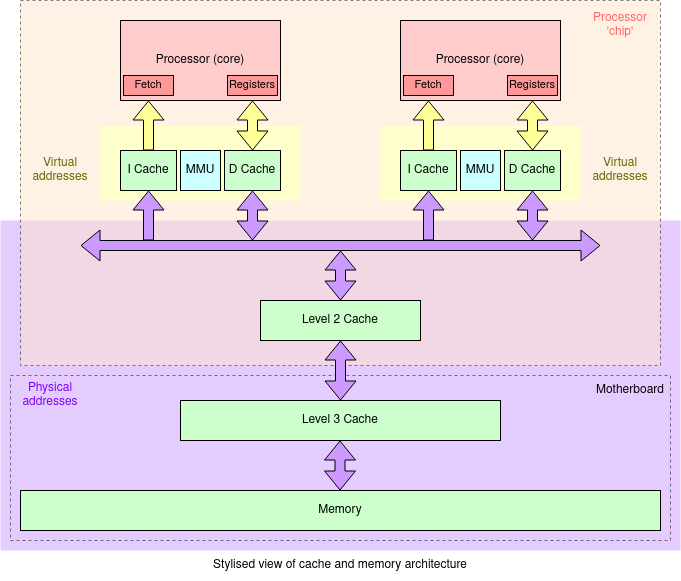
In a multicore system with multiple cache levels some, at least will be shared amongst the various cores (processors). The level 1 caches will be private since they must provide both low latency and high bandwidth for their adjacent core. A lower level cache needs to provide enough bandwidth to service the cache misses from all the processors ‘above’ it without stalling for any appreciable interval. This, in turn and in combination with the cache's cycle time, determines how many cores can share a cache before the performance collapses.
The figure above shows just one possibility for a cache structure;
many variations are possible. For example there may be
‘private’ level 2 caches, sharing only at
level 3. Increasingly the level 3 cache may be on the
processor chip. Sometimes there will be more or fewer cache
levels.
A significant trend is an increase in the number of processor cores
which may share the buses further down the hierarchy. Sometimes the
structure may look more ‘tree-like’, with a mid-level
cache divided and shared amongst subsets of the cores. This reduces
the bandwidth ‘pressure’ on any single bus segment and
means the buses can be physically shorter – and, thus,
faster.
Research: You might like to look up some contemporary examples of cache hierarchies.
Since caches take copies of the memory, when there are several caches at the same level (such as in the multiprocessor above) there could be multiple copies of a single item. If a processor modifies one copy any others become out of date. This is dangerous.
We will address this later, although you might want to do your own research on cache coherence.
Memory latency can severely impact performance. Cacheing alleviates this providing the desired values are in the cache. To reduce cache misses it is possible to prefetch cache lines, speculating on what might be wanted in the near future.
Discussion problem
- What disadvantages might result from speculative cache prefetching?
- What sort of algorithm(s) might be applied to predict future load addresses?
In what circumstances might each algorithm be effective?- How/when might prefetching be achieved in software?
What are the benefits and penalties of attempting this?- How/when might prefetching be achieved in hardware?
What are the benefits and penalties of attempting this?
Next: write buffers. and a bit more on caches