A computer program – or, at least, a single thread in a computer program – is an ordered list of statements. When you write the code you rely on this order.
The source code is compiled into object code. The compiler may change the order of instruction op-codes from the ‘obvious’ order by swapping some around, which is legitimate as long as there are no dependencies between them. This may bring performance benefits.
ldr r1, [r2] ;
add r1, r1, r1 ; Depends on load
sub r2, r2, r3 ;
might suffer from a stall, waiting for
ldr r1, [r2] ;
sub r2, r2, r3 ; Can 'sneak' in between!
add r1, r1, r1 ; Depends on load
harmlessly, with the
A ‘binary’ file may be produced which runs on all processor implementations but can still benefit from some reordering. Some compilers will offer options to order instructions to perform best on particular processor microarchitecture.
Some high-performance processors will reorder instructions even if the
compiler has not. This is ‘out of order issue’ –
but more of that later. The important point is that the code should
still behave in the way the programmer expected.
The really unpleasant problem here is if something upsets the expected
order: if the processor only has the first code above but swaps the
instructions and issues them in the second order and then the
load faults and causes an exception then it's hard to
reconstruct what should have happened.
It is possible to fix this sort of thing. Stay tuned because it's
covered later.
Changing the order of operation execution is a general technique which
can improve performance. Another example is the write buffer
which can allow more urgent reads to overtake writes.
Again, good unless something goes wrong; there can be problems and
the illusion that operations are ordered needs to be
maintained.
A place in the code (thread) where it is guaranteed that everything required previously has been completed and nothing later has been committed to is sometimes called a ‘sequence point’.
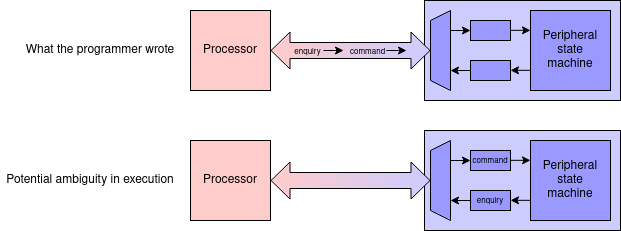
A typical peripheral interface device will have a number of
addressable registers. The sort of functions these may include might
be a command register and a status register, which may
be at different addresses.
An operation may involve writing a command then waiting until the
status indicates the device is ‘not busy’, meaning that
the operation is complete. If these are sent (in that order) by a
processor the read must not be allowed to overtake the write (think
about it!) which it could if there was an intervening write
buffer.
Note that the usual forwarding would not prevent this if the
addresses were different.
Thus, I/O areas should be unbufferable as well as uncacheable.
‘Ordinary’ RAM can usually be written in different orders harmlessly – as long as two stores to the same location are kept in order (which is a ‘WAW hazard’ (discussed elsewhere). However there are times when this could cause problems. Consider a multi-threaded system where (for example) one processor is filling a data buffer after which (as the the programmer writes it) it stores a flag which validates the block. If this happens out of order when another processor has a thread which waits for the flag then reads the data ... consider what might happen.
But how could such a thing happen?
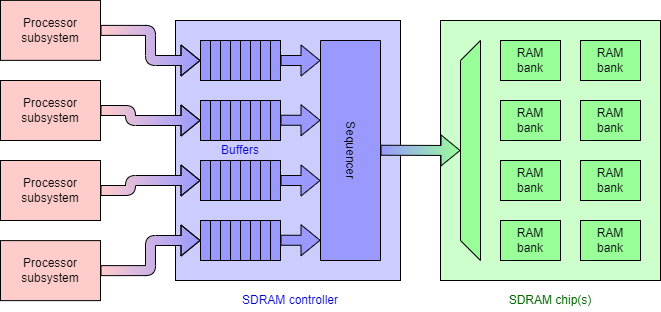
Whilst unlikely, consider (for example) an SDRAM controller managing
near-simultaneous incoming requests. Indeed, some RAM controllers
will have multiple interfaces each with a buffer, and will try to
sequence commands from its buffers to keep the actual SDRAM chip(s)
busy. Remember there are delays as rows are opened and closed
and access to different banks may be interleaved, so some
reordering is generally beneficial.
So can it be fixed?
There may be
memory
barrier (sometimes called a “fence”) instructions
which can be inserted in the instruction stream. This basically means
‘finish all the operations before this point
before starting any after it’. In the previous
example this would ensure the store operations happen with the
necessary separation.
It would not, of course, compel any synchronisation between
independent threads on independent processors.
In most cases compilers (and processors) will safely and beneficially reorder operations. Most occasions where this needs to be controlled occur in embedded programming or in libraries, dealing with I/O devices etc.
There is not space to go into all the ramifications here. Some
control is sometimes available, such as declaring an item as
‘
Further reading (interest only): this article might help illustrate some of the potential for confusion.
Before you ask, there will not be exam. questions on this!
Most memory has a single port which means that only one operation (either a read or a write) is possible at any time. The memory is modified by a processor, which must successively read the value, modify it and write it back. When more than one (notionally) concurrent thread might modify the same memory location there is a danger that these successive operations might interleave in an ‘embarrassing’ way.
Thread A Thread B
Read
Modify Read
Write Modify
Write
In this example any modification from Thread A is lost. This would be
a Bad Thing.
Atomicity of the read-modify-write operation should be preserved.
Thread A Thread B
Read
Modify Read ... Not yet
Write Read? ... Still busy
Read ... Okay now
Modify
Write
At the bus level this can be done with an additional signal:
‘lock’. This is asserted by the read and it
prevents access to that location – and, quite possibly, the
whole shared bus – from any source except the locking one until
the corresponding write is complete.
(Note that this may be some
time: the modification may be quick but the load and store cycles may
take a considerable time in ‘distant’ memory.)
(Dumb) questions: why not cache the location?
What's stopping it being cached?
Most operations don't care about this so lock is only used on
‘special occasions’. Any processor intended for
multiprocessor systems will have a means of achieving this or some
comparable protection mechanism.
Some examples:
These rare-but-important operations all assert a hardware bus-lock
signal.
Note that the logical behaviour of the bus needs to be preserved, even
if the information is carried in a different way, such as a serialised
bus
(e.g. PCIe) or
a network-on-chip.
This will be revisited from the processor view later.
Note that the principle is not just applicable to RAM
locations: a similar problem occurs in (for example) databases where
it can be handled purely by software.
Further reading (interest only): transactional memory – another solution.
Another synchronisation issue when multithreading is preventing some threads from passing a synchronisation point before other, parallel threads have reached it. For example, if drawing graphical objects there is clearly an opportunity for considerable parallelism but no thread should move to the next (animation) frame before all the current picture is complete.
Whilst important, this is usually the responsibility of software (at least at the moment!) so is of less interest from an architectural perspective. It's mentioned here for completeness – and for an excuse to include this demonstration by a former student.
This could be implemented with a shared variable, initialised
with the number of parallel threads. On arrival at the barrier each
thread decrements the variable (once) and waits to proceed, rereading
the variable until it is zero.
Note that multiple threads write to a shared location so there must be
atomicity of the read-modify-write operations so there is still,
ultimately a hardware involvement in ensuring this will work properly.
Next: Memory Management Units